In the last two posts (here and here) I have documented how I use gMSAs to connect services running in docker containers on Windows to SQL Server using the domain authentication. In the end it was very simple, but there are things I wish I knew when I started. It would save me a lot of time. Here is an attempt to document the lessons learnt.
Versions are important!
While in the end I was able to make it work on Windows Server 2016, 1803, 2019 and 1809 I wasted some time trying to make it work with docker 17.06. Unsuccessfully. Docker 18.09.1 and 18.09.2 worked every time.
There are some reports of intermittent problems with specific OS updates breaking stuff, like the one here but I wasn’t able to reproduce it. I wonder if the updates changes something else that it causing problems, in other words is it the problem with the update itself or the update process?
The Set-AdServiceAccount
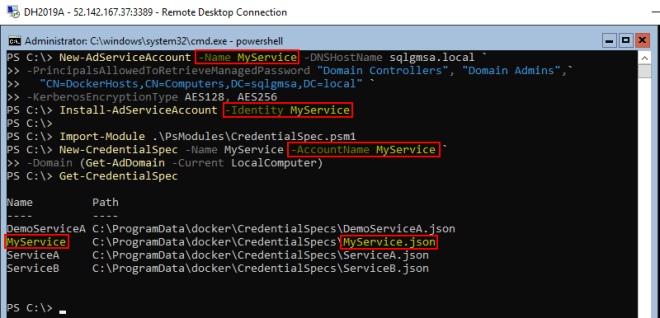
From the beginning I set to try the gMSA authentication on multiple VMs following blog posts which all included some use of the Set-AdServiceAccount powershell command (from `RSAT-AD-PowerShell). I could not make it work on more than one VM at a time. I thought I was going mad! The problem (and the clue) is in the name. Set. It is not add, not modify. So when I was doing something like this
Set-AdServiceAccount -Identity MyService ` -PrincipalsAllowedToRetrieveManagedPasswords DH2019A$
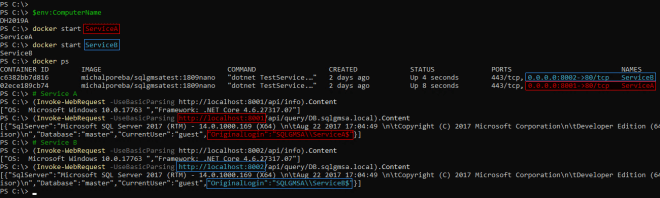
it was setting the principals allowed to retrieve the managed passwords for MyService to DH2019A VM. As expected. But not as expected removing the privilege from all the other VMs I granted that permission before. With no warnings.
It is probably the most worrying part about using gMSAs for the service authentication in production, as I plan to do it. All it will take is one sysadmin to run a command like that to break all the services, potentially on all docker hosts. To mitigate we have decided to grant the permissions through a domain group to which we will add docker hosts. That way there should be no need to run this command when scaling out.
Misleading Get- and Test-AdServiceAccount
Understanding the above problem with Set-AdServiceAccount was made much worse, by my misunderstanding how Get-AdServiceAccount and `Test-AdServiceAccount work.
If you are a domain admin the Get-AdServiceAccount will always return details of the gMSA if it exists. So it is of no use to check if the specific gMSA can be used on a given host.
If the gMSA was previously installed the Test-AdServiceAccount will return true regardless if the host account has permissions to retrieve the password or not. That permission is necessary for the gMSA authentication to work.
So with that in mind neither command is fit for checking if a specific host has permissions it needs to use a gMSA. I was not able to find anything better than attempting to install it again with Install-AdServiceAccount. It will either install it again, or display error message indicating that the computer has no permissions to retrieve the password.
Remove-AdServiceAccount
This does not remove previously installed gMSA from the local host. It removes the gMSA from the domain!
The SSPI context error.
If you try to use domain authentication from the service running on a docker host which has no permissions to retrieve the gMSA password you will get fairly generic error tell you that the SSPI context couldn’t be created.
There are scores of blog posts and msdn documents explaining how to troubleshoot many SSPI context errors. Not a single one I found mentions any problems with gMSA. I have learnt a lot about SSPI and how it really works, just to eventually realise that everything is fine, and I have to look for problems somewhere else.
There is no localhost
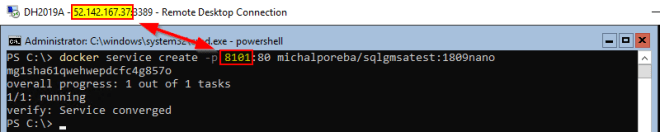
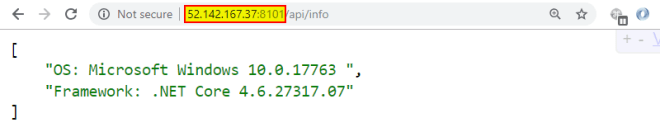
When you run a standalone container you can access it from the same host on the localhost. By default a nat network is used and it allows communication on the hosts IP. When moving to the swarm mode (using docker service create not just docker create) by default the ingress network is used and the localhost is not available. You have to use the public IP address of the docker swarm. There is a lot of blog posts how to define your own overlay or bridge networks. I suppose they all work on Linux, but on windows when using an overlay network you cannot use host IPs (so no localhost) and you cannot create bridge networks at all.
PS C:\> docker network create -d bridge bnet Error response from daemon: could not find plugin bridge in v1 plugin registry: plugin not found
I was able to make it work when publishing the port directly on the host using --publish published=8001,target=80,mode=host instead of the shorter -p 8001:80 (ports obviously may be different) but I don’t think that’s a configuration I’d be using so… I simply gave up. I use public IP and everything works.
Security considerations
To install a gMSA on a host which has permission to read the gMSA’s password you don’t need to have any extra permissions. It appears that anybody with access to PowerShell on the host can do Install-AdServiceAccount -Identity MyService. There are no restrictions which credential spec file can be sued for which servce either. This means that if somebody has access to the docker host they can create a new service using any gMSA to which the host itself has permissions.
gMSA name lenght limit
The Group Managed Service Account’s name is limited to 15 characters. Not a big deal, but it messed up a carefully agreed naming strategy and in the end I have vowel-less service names.
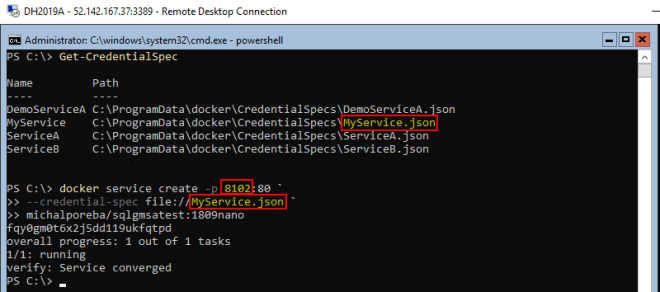
New-CredentialSpec silently overwrites existing files.