
Have you heard claims that in SQL Server the new JSON data support performs 10 times better than the old XML storage? And all that despite using nvarchar type for storage instead of the specialised xml type. Claims like this one on blogs.msdn.microsoft.com. I used to do a lot of XML in SQL Server and now I use JSON too so I decided to check how they compare when it comes to performance in SQL Server (2017).
Setting the Scene
XML Data Type has been supported by SQL Server since version 2005. It was implemented as a new built-in data type. It is possible to define a column as an XML type with, or without schema and then query the non-relational data together with relational data. It came with for xml clause and three main methods: modify, query and value defined on the XML type.
Let’s see an example of retrieving a value of a node from an XML variable:
declare @xml xml = N'<Test>123</Test>'; select @xml.value(N'(//Test/text())[1]', N'int');
JSON support was introduced in SQL Server 2016. That’s right, JSON support but not a JSON type. The data is stored as plain text, something that was possible before of course, but there is for json clause and 4 methods: isjson, json_modify, json_query and json_value.
An example of retrieving value from a JSON document can look something like this:
declare @json nvarchar(max) = N'{ "Test": "123" }';
select json_value(@json, '$.Test');
It would be difficult to compare performance of every single usecase so I have decided to focus on comparing single value retrieval from a document using .value and json_value for XML and JSON respectively.
Sample XML document
<test> <row key="ValueA" value="123" /> <row key="ValueB" value="-432" /> ... <row key="ValueZ" value="849" /> </test>
Sample JSON document
{
"ValueA": "123",
"ValueB": "-432",
...
"ValueZ": 849"
}
I have tables created where there are only two columns, an integer primary key Id and a Data column of the test type. The tables are populated with 100,000 random records. The test consists of simply calculating a sum of a specific property from the document across all the rows in the table. To put things in perspective I will compare performance on the document types to aggregate on an int and an varchar type columns.
Test XML query
select sum(
[Data].value('(//test/row[@key="ValueA"]/@value)[1]', 'int')
)
from dbo.XmlData
Test JSON query
select sum( convert(int, json_value([Data], '$.ValueA')) ) from dbo.JsonData
There are no indexes or computed columns to help with the performance of the queries as the objective is to simply measure performance of parsing and document querying.
First Comparison Results

That can’t be right!? Can it? JSON query took on average of 0.43 seconds which is 36 times faster than the 16.79 seconds it took to sum the values out of the XML documents. Better (or worse) still when compared to an XML with schema which took 40.47 seconds the JSON type seems to be 94 times faster. So what happened to the 10 times faster claim? Well, the native VARCHAR column performed 10 times faster at 0.04 seconds than the JSON one. the INT column was still faster at 0.03 seconds.
It is also worth looking at the logical reads. Native INT and VARCHAR columns required just over 200 logical reads while both JSON and schema-less XML took around 12,000 logical reads, while the XML with schema required over 34,000.
Playing with storage types
The above were rather unexpected results. Both in terms of CPU and the logical reads. And that got me thinking, what if I could reduce the number of reads? The simplest way to do so would be to reduce the size of data by changing the types. I have created additional tables with the exact copy of the JSON test records but using VARCHAR(max), NVARCHAR(512) and VARCHAR(512) types in addition to the standard (as in most common in all the examples I have seen) NVARCHAR(max).
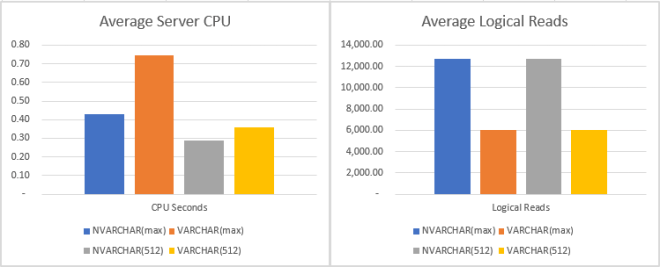
Another surprise! As expected using VARCHAR instead of unicode NVARCHAR halved the number of logical reads but that didn’t translate to improved CPU times. Using json_value on VARCHAR(MAX) was significantly (and consistently) worse than the same method on NVARCHAR(MAX). Specific maximum length types performed better than the the types with the max length but there too unicode required less CPU time despite having twice as many page reads.
At the beginning or at the end
So is it really possible that the old XML type is 36 times worse than on-the-fly JSON parsing? Perhaps there are some benefits to XML storage? I’d imagine the JSON parser is clever enough to stop parsing after the first matching node is found which probably means that the performance will depend on weather we are looking for a value of a property close to the beginning or close to the end of the document? And, perhaps, that’s where XML will perform better being pre-parsed type? I have modified the tests to look at the first and last values from the documents.
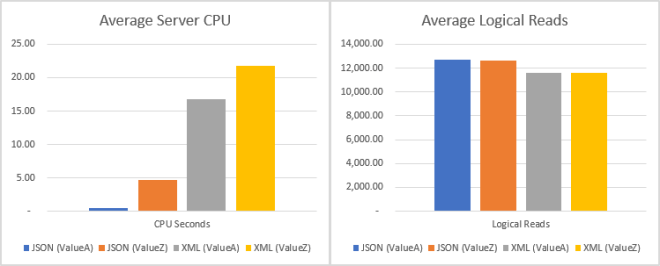
Here the results were more as expected. When using json_value on a NVARCHAR(max) data ValueZ being at the end of the document structure performed worse than ValueA which is at the beginning. In fact ValueZ queries took 10 times longer than ValueA. XML still has shown differences but ValueZ queries took only 30% longer than the ValueA ones. Still worst case JSON query was 4 times faster than the best case XML query!
Storage
So that shows that JSON on unicode types uses less CPU time but requires more logical reads which suggests more pressure on RAM and potentially more I/O. How does the storage requirements of all those types compare?

XML with Schema is the most expensive in terms of storage, by quite some margin. Despite being visually more verbose the XML type actually takes slightly less disk space than the unicode json which is twice as much as non-unicode json. As one would expect the standard INT columns require least.
Conclusions
JSON data in SQL Server 2017 really is faster than the old XML type. How much faster will depend on the position of the specific value in the document. That’s important, the structure and ordering of properties in the document matters. If you are in control of the JSON document structure consider putting properties more likely to be queried at the beginning of the document and those you know you will index at the end so that you don’t have to parse through them when working with properties which are not indexed. Types matter too. NVARCHAR is faster than VARCHAR but will use twice logical reads (and therefor RAM). Specific lengths perform better than using (max).
